A model is static. The substrate it consults is not. Customers ask new questions. Policies shift. Workflows that resolved cleanly six months ago start producing edge-case escalations. Documents the team relied on quietly age out of relevance. A system without a learning loop ships once and then accumulates rot. A system with one ships and then improves continuously.
The learning loop is what closes the system.
The policy nobody had written down
Mid-March 2026: DeltaBank’s customer support agent, the same one that handles Maria’s late-fee dispute was running through its usual ~12,000 cases a day. Most resolved cleanly. But over the course of two weeks, five different customers asked some version of the same question:
“Can I send a wire transfer from my Platinum account to my daughter’s account in Paris?”
The agent couldn’t find an answer. Each time, it escalated. Each time, a human rep handled by usually emailing the Treasury team. By the third escalation, two reps were grumbling about it in the support team’s Slack channel. By the fifth, someone wrote up a quick policy explainer and stuck it in a Google doc. Nobody bothered to put it in the trusted knowledge base. That took filing a ticket with the knowledge team and waiting for review.
Six weeks later, customer #11 asked the same question. The agent gave the same non-answer. The customer escalated to social media. The post went mildly viral. Compliance got involved. The Treasury team’s “quick explainer” turned out to be incomplete, it missed the corridor restrictions that mattered for the specific country. Now there was a policy gap and a compliance incident.
The fix wasn’t that the answer was unavailable. The fix was that the system never noticed it was missing.
A serious learning loop would have caught this around case #3 or #4. The pattern was visible in the data: five separate customers, similar phrasing, the same agent escalation, the same human-rep workaround happening over and over in Slack. Nightly trace mining could have surfaced the gap within days of the second occurrence. The flagged knowledge gap would have routed to the Treasury team’s queue. A policy would have been written, promoted to trusted knowledge through the construction harness, and the agent would have had a clean answer by case #5 — instead of case #12 after a compliance escalation.
This is what the learning loop is for.
What the learning loop actually does
The previous four pillars cover building the system:
Memory gives the agent something to remember (the substrate).
Retrieval gives it a way to consult what it remembers.
Tools and actions give it ways to do things.
The harness wraps it all in deterministic discipline.
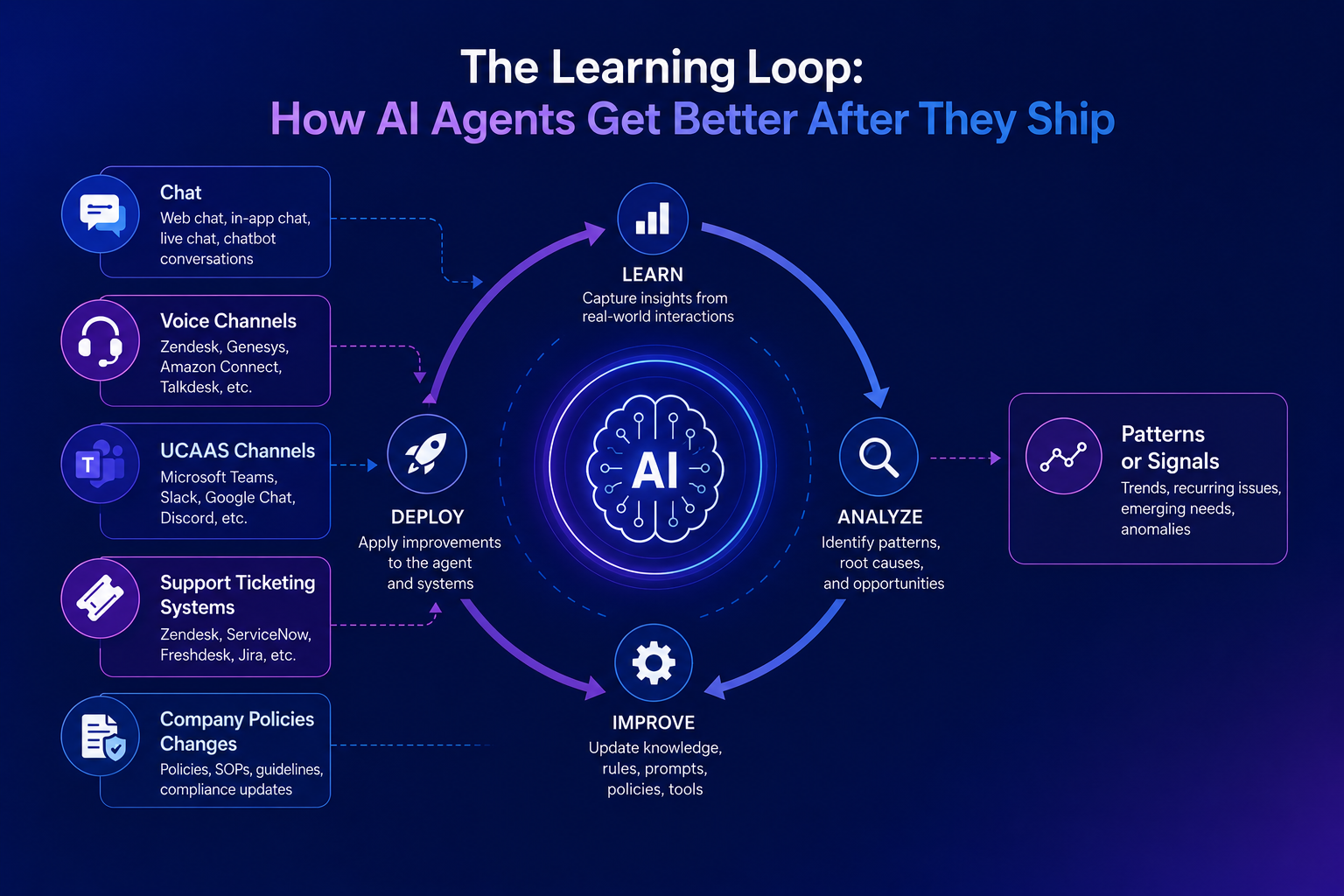
The learning loop is what keeps those four pillars from going stale. It is the discipline that:
Watches every conversation, decision trace, and channel where humans are solving problems the agent should eventually handle.
Identifies patterns the system should learn from — knowledge gaps, conflicts, drifts, edge cases, repeated workarounds.
Routes signal through human review where judgment is needed; auto-applies where it is safe.
Closes the loop by feeding approved changes back into the substrate, the harness, the tool registry, the prompt set, and the metagraph patterns.
Without a learning loop, the harness only grows by accident — someone files a ticket after an incident, an engineer adds a rule, the substrate stays whatever it was on day one minus whatever rot accumulates. With a learning loop, the system improves continuously, and improves automatically on the dimensions where automatic improvement is safe, while routing to humans on the dimensions where judgment is required.
A clean operational definition: the learning loop is the mechanism that turns observed signal into durable change.
Two domains, one loop
The learning loop fires across two distinct domains, with different trigger sources and different review patterns. Most treatments of the topic cover the first and ignore the second — which is the half that actually compounds over time.
Runtime domain — what goes wrong (or right) during a live case
Wrong tool picked. Retrieval missed. Customer escalated. Audit flagged something. Cases that succeeded but with low groundedness, retries that should have been one-shots, response times far off baseline, conflict signals where the agent retrieved two contradicting policies.
Signal sources in the runtime domain:
Decision traces from every closed case (stored in episodic memory, queryable for patterns).
Escalation events and the reasons humans gave for taking over.
QA corrections by review teams who graded agent responses.
Customer satisfaction surveys and the topics where scores degrade.
Eval-suite regressions when harness rules change.
Trusted knowledge domain — what’s wrong inside the substrate itself
This domain has nothing to do with any specific case. It is about the substrate’s own health. Two trusted facts contradict each other. Two :Customer nodes that should be one entity were never merged. A document’s last_reviewed date has passed threshold. A source consistently produces low-confidence extractions and should probably be deprecated. A recurring zero-result query pattern reveals a knowledge gap.
Signal sources in the trusted-knowledge domain:
Nightly conflict-detection passes over the graph.
Duplicate scans over entity-resolution candidates flagged during construction.
Zero-result query pattern analysis (the wire-transfer story above).
Last-reviewed staleness alerts.
Provenance-health monitoring on extraction confidence over time.
Both domains feed the same loop. Both produce durable changes. The discipline is unified; the trigger sources differ.
The signal surface — every channel humans use to solve things
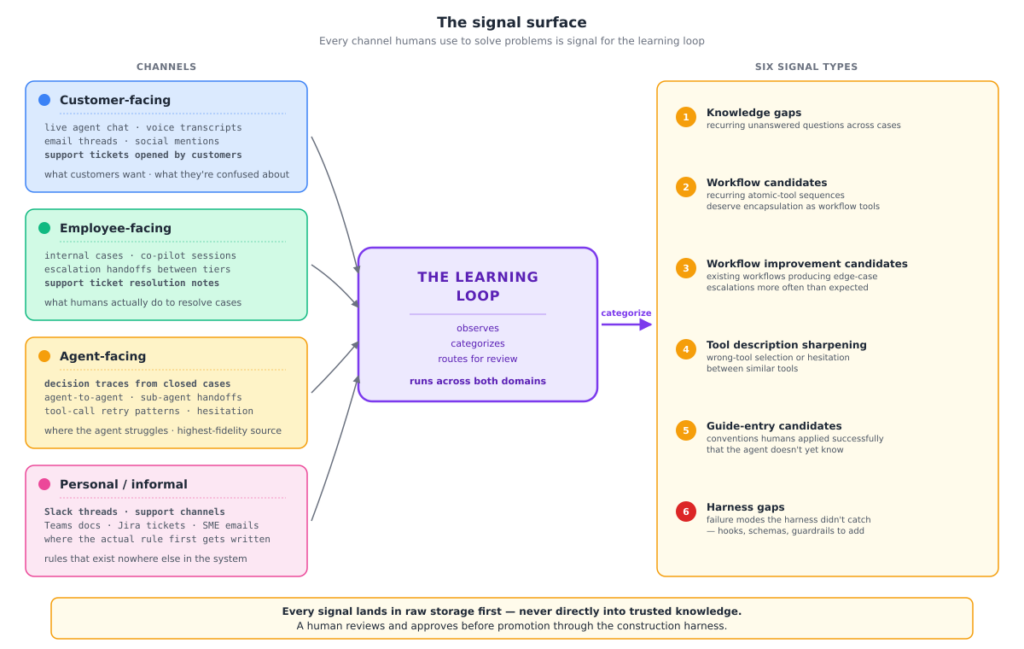
A good learning loop doesn’t just watch what the agent does. It watches what humans do to compensate for what the agent can’t yet handle. Four channel categories matter, and most production systems under-observe at least two of them.
Customer-facing channels: Live agent chat, voice transcripts, email threads where the agent assisted or escalated, support tickets opened directly by customers, social mentions where customers describe problems publicly. These reveal what customers actually want, what they’re confused about, and what the agent couldn’t answer.
Employee-facing channels: Internal cases between reps and customers, agent-rep co-pilot sessions, escalation handoffs between support tiers, the resolution notes and closure comments on support tickets — the actual back-office work that finishes what the agent started. Support tickets are a particularly rich source: they carry the customer’s original framing, the rep’s diagnosis, the resolution path, and the outcome, all in one structured record. These reveal what humans actually do to resolve cases — which workarounds keep recurring, which workflows the agent doesn’t know exist.
AIAgent-facing channels: Decision traces from every closed case, agent-to-agent communications in multi-agent systems, sub-agent handoffs, tool-call retry patterns, the agent’s own reasoning through edge cases that didn’t match its existing patterns. Decision traces are the highest-fidelity signal source the loop has, they show exactly which tool the agent reached for, which retrievals fired, which paths it considered. Most of the runtime-half of the learning loop is built on trace-mining.
Personal / informal channels: Slack threads where senior reps debate how to handle an edge case, dedicated support channels where escalations get worked in the open, Teams documents where PMs update policies before they’re formally published, Jira tickets where engineers note exceptions, the SME emails where the actual answer to a customer question gets written down for the first time. Often the most valuable signal source, because they capture rules that exist nowhere else in the system.
Across all four channels, the learning loop watches for six signal types:
Knowledge gaps: Recurring questions the agent or human reps couldn’t answer with confidence. Multiple instances over a window become a flagged gap, not a one-off. The wire transfer story is this.
Workflow candidates: Patterns where the same sequence of atomic actions resolves a recurring case type successfully. Ten cases tells the system the pattern is real and deserves a workflow tool.
Workflow improvement candidates: Existing workflows that produce edge-case escalations more often than expected. Suggests a missing branch or a refinement.
Tool description sharpening: Situations where the agent picked the wrong tool or hesitated between two. The descriptions probably need tightening.
Guide-entry candidates: Corrections, exceptions, and conventions that humans applied successfully but the agent doesn’t currently know.
Harness gaps: Failure modes the harness didn’t catch, hooks that need to be added, schema validators that need to be extended, guardrails that should have fired but didn’t. Every incident is a candidate for a new piece of harness.
The architectural rule, carried over from the construction harness: every signal lands in raw storage first, never directly into trusted knowledge. A human reviews and approves before promotion. The construction-harness gates run during promotion, just as they would for any other ingestion path. The cost of not ingesting a signal is usually lower than the cost of poisoning the substrate. When the loop is uncertain whether a flagged pattern is real, it surfaces to review rather than promoting silently.
From signal to durable change: the four-phase loop
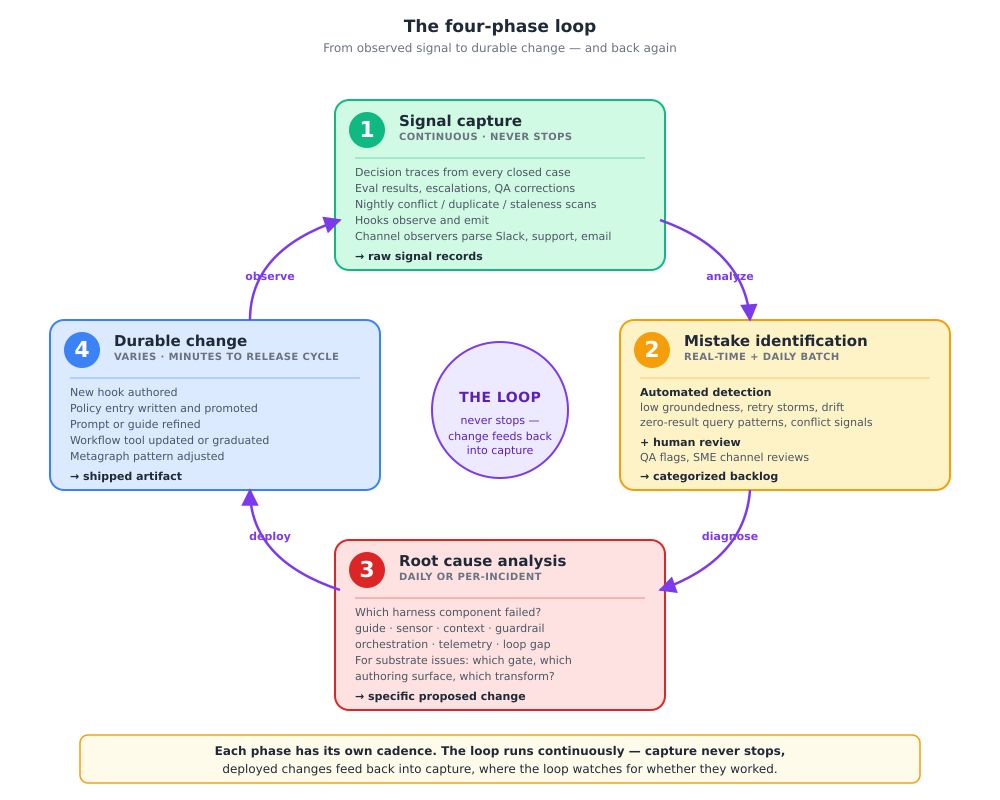
Once the learning loop has signal, what does it actually do with it? Four phases, in order, each with its own cadence.
Phase 1 (Signal capture): The runtime harness records decision traces, eval results, escalation events, QA corrections, customer satisfaction scores. The trusted-knowledge layer runs nightly scans for conflict, duplicate, and staleness. Hooks observe and emit. Channel observers parse Slack threads, support cases, and email archives into structured signal records. Nothing analytical yet, just data acquisition. This phase is continuous; it never stops.
Phase 2 (Mistake identification): A combination of automated detection and human review. Automated: low groundedness scores, retry storms, escalation rate exceeding baseline, conflict detection, zero-result query patterns, drift in workflow success rate. Human: QA team flags incorrect agent behavior, SMEs review channel observations for actionable patterns. Phase 2 outputs a categorized backlog of candidate changes. Cadence: real-time for severity events, every few hours for batch detection, daily for human review.
Phase 3 (Root cause analysis): Diagnose which harness component or memory artifact is the source of the problem. The “When the harness fails” diagnostic framing from the harness post is the starting point — guide gap, sensor gap, context gap, guardrail gap, telemetry gap, orchestration gap, loop gap. For trusted-knowledge mistakes, the question is which substrate gate, which authoring surface, or which extraction transform needs the change. The output of Phase 3 is a specific proposed change, attached to a specific artifact.
Phase 4 (Durable change): The fix propagates back to the appropriate artifact. New hook authored. Policy entry written and promoted. Prompt refined. Workflow tool updated. Conflict-adjudication rule changed. Tool description sharpened. Each fix goes through the appropriate review path, some auto-apply for low-risk changes after passing an eval suite, some require human review and a full release cycle for changes that govern agent behavior broadly.
Different changes have different deployment timelines. A tool-description tweak can deploy in minutes after a passing eval. A new workflow tool deploys with a regular release cycle. A metagraph pattern change deploys with extra care because it changes behavior across many cases. The more an artifact governs the agent’s behavior, the higher the review bar for changes.
Hooks: from defense to generation
The harness post framed hooks as gates — schema validators, permission checks, idempotency guards. That framing is correct but incomplete. Hooks are also the system’s primary observation surface. Once a hook is observing, it’s a small step from observation to proposal.
Three hook patterns matter for the learning loop:
Session-end stop hooks: When a case closes, the stop hook reflects on it while context is still fresh, which tool did the agent reach for? Did it match what the workflow expected? Were any retrievals zero-result? It produces a structured proposal (candidate guide entry, tool description tweak, metagraph refinement) and queues it for review, the same queue as any other channel-observed signal.
Session-start hooks: When a case opens, the start hook dynamically loads the right slice of organizational context. A Platinum fee dispute pulls in the Platinum policies and the dispute-handling guide. A fraud case pulls in the fraud skill and compliance constraints. The hook keeps working memory targeted, and it records which context was loaded so the loop can later analyze whether the load was correct.
Periodic background hooks: Nightly or weekly, they scan the substrate for trust-decay alerts, drifting workflow success rates, orphan nodes, duplicates, garbage-collection candidates. They emit signal into the loop’s queue with no human in the trigger path.
This reframes the harness substantially:
The same hook that prevents a bad tool call from firing can also be the hook that proposes a new guide entry to prevent the next bad tool call from being attempted in the first place.
Defense becomes generation. The harness and the learning loop share a single mechanism — used for different purposes.
What the loop actually changes
The output of the learning loop falls into three categories: substrate changes (what the agent knows), harness improvements (the rules and gates around the agent), and configuration changes (prompts, tool descriptions, workflows).
Substrate changes
Facts corrected when the loop surfaces contradictions or QA flags incorrect responses.
Policies refreshed when last_reviewed thresholds trigger.
Decision traces annotated as failures or exemplars so future trace-mining can weight them.
Knowledge gaps are directly filled into trusted knowledge by an authority, or via raw storage with promotion through the construction harness.
Harness improvements — both construction and runtime
The category most teams under-invest in. Every incident and near-miss is a harness candidate, and the loop turns those into durable additions.
Construction gates: Entity-resolution thresholds tuned after bad merges, schemas extended for new fields, provenance rules tightened when audit reveals gaps.
Runtime hooks: New pre/post hooks added when failure modes appear, existing hooks relaxed when the model improves and they become friction.
Guardrails: Permissions tightened or expanded by actual usage, scope adjusted when new roles roll out.
Eval suites: New test cases added whenever a real failure escapes existing coverage. The loop’s incident log is the eval suite’s growth path.
Conflict rules: When two trusted facts repeatedly disagree, the adjudication rule gets updated.
The principle from the harness post applies: every hook, every gate, every rule traces to a real past failure. The learning loop is the mechanism that turns yesterday’s failure into today’s hook without waiting for someone to file a ticket.
Configuration changes
Prompts: System prompts, guide files, AGENTS.md, domain policy markdowns updated based on what the agent kept getting wrong.
Tool descriptions: Sharpened so the model picks the right tool more often.
Workflow definitions: Refined when observed atomic-tool sequences suggest cleaner branches; new workflows authored when recurring patterns earn encapsulation.
Multi-party review (PM, eng, compliance) → ship with release
Metagraph pattern change
Careful review (behavior change across cases) → ship with release
Conflict-rule change
Compliance + PM review → ship with release
The more an artifact governs the agent’s behavior, the higher the review bar for changes. A tool description tweak that the eval suite validates deploys in minutes. A new metagraph pattern needs careful review — it changes retrieval for every matching case.
The four disciplines — how the learning loop fits with everything else
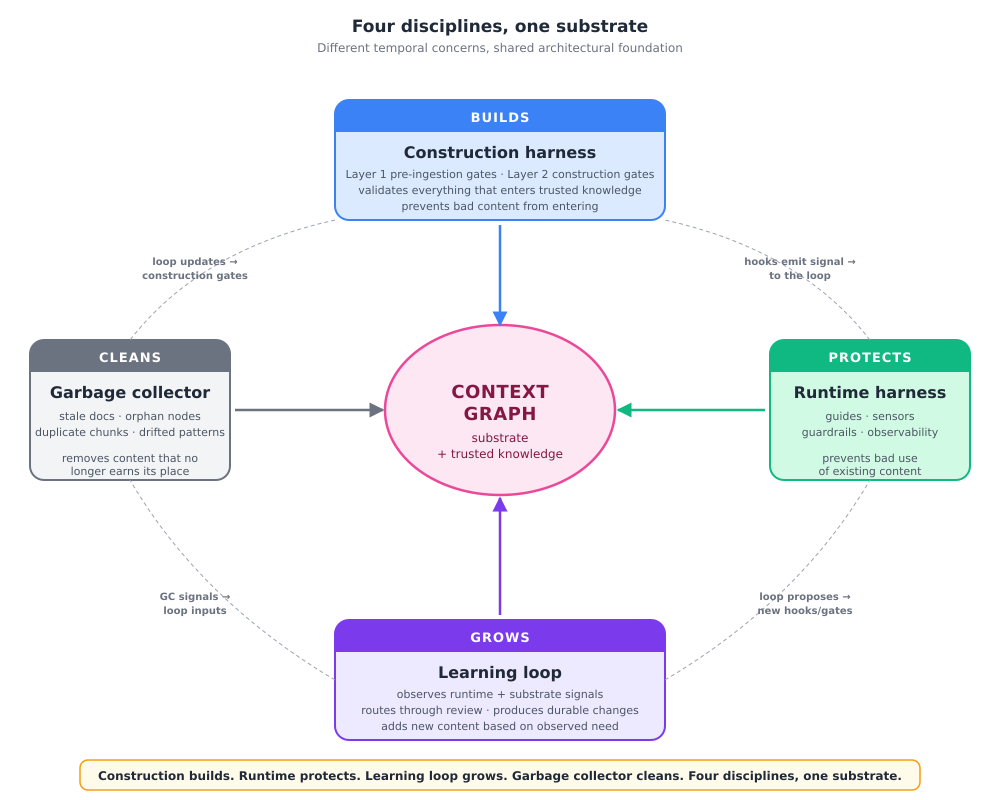
The harness post named two disciplines — construction harness and runtime harness. The full picture has four, all operating on the same substrate:
The construction harness builds the substrate. Layer 1 pre-ingestion gates, Layer 2 construction gates. Validates everything that enters trusted knowledge.
The runtime harness protects the substrate during live cases. Guides, sensors, guardrails, observability. Validates everything the agent reads or writes.
The learning loop grows the substrate. Watches signals from runtime and from trusted knowledge itself. Routes findings through review. Produces durable changes to memory, harness, prompts, tools, workflows, and metagraph patterns.
The garbage collector keeps the substrate clean. Scans for stale documents, drifting workflows, orphan nodes, low-groundedness traces, duplicate chunks, outdated metagraph patterns. Proposes pruning candidates for review.
The disciplines are tightly coupled. GC signals (drift, orphans, low groundedness) feed the learning loop. Loop outputs (new workflow tools, refined patterns) drive GC priorities. Runtime hooks feed both the loop (improvement candidates) and the GC (freshness signal). Construction gates run during initial ingestion and during loop-driven updates — same gates, different trigger.
The framing line worth keeping:
The construction harness builds the substrate. The runtime harness protects it. The learning loop grows it. The garbage collector keeps it clean. Four disciplines, one substrate.
When the learning loop fails
Same diagnostic discipline as the runtime harness. When the loop fails to produce improvement, the question is which phase failed?
Loop never noticed the signal → Phase 1 capture gap. Channel coverage is incomplete, hooks aren’t emitting, or trace mining isn’t covering the relevant clusters.
Loop noticed but didn’t flag it → Phase 2 identification gap. Detection thresholds are wrong, the queue is over-filtering, or human reviewers don’t have visibility into the right signals.
Loop flagged it but the team didn’t act → Phase 2/3 ownership gap. No clear DRI for the affected artifact, or the review queue has no SLA.
Team acted but the fix didn’t work → Phase 4 deployment gap. The change shipped, but it addressed the wrong root cause, or it lacked an eval that would have caught the gap before deployment.
Fix worked but recurred later → Substrate-rot gap. The garbage collector isn’t pruning what the learning loop superseded, so the old version keeps influencing retrieval.
Each failure mode has a clear remediation, and each becomes its own piece of the harness over time. The learning loop, in other words, learns about itself.
Closing — the loop closes the system
The harness post made the point that the harness and the model co-evolve. The learning loop is the mechanism by which they do. Useful primitives discovered through the loop — better tool descriptions, sharper guide entries, tuned metagraph patterns — feed back into the substrate. Some eventually feed back into model training, as the next generation is trained on patterns the previous generation’s harness surfaced.
Three takeaways for the Learning Loop pillar:
The loop runs across two domains, not one. Runtime mistakes and trusted-knowledge mistakes both feed the same discipline. The substrate half is where the compounding happens.
Every channel humans use to solve problems is signal. Customer chat, employee escalations, agent traces, Slack threads, SME emails. The most valuable signals are often in the informal channels that capture rules existing nowhere else.
The harness becomes generative. Hooks aren’t just gates — they are observation surfaces that propose improvements. The same primitive that catches today’s mistakes generates tomorrow’s prevention.
This is the fifth and final pillar of the system of intelligence series. Memory gives the agent a substrate. Retrieval gives it access. Tools and actions give it capabilities. The harness gives it discipline. The learning loop gives it the ability to improve.
Together they describe what enterprise AI looks like when it’s built to last, a system that gets better at its job every week, with humans steering where judgment is required.
Comments
Leave a Comment
No comments yet. Be the first to comment!
Written by Prasanth Sai
Gen AI Product Leader · Leads AI Applications and Search at eGain
I partner with PMs and engineers to drive production adoption of AI across Fortune 500 enterprises in the US and Europe. IIT Bombay alumnus; previously co-founded Selekt.in and built ChatGen.ai. The thesis I evangelize: knowledge is the harness for AI applications.
Enjoyed this article?
Explore more insights on Gen AI, product leadership, and enterprise AI transformation.