A model writes confident answers and calls tools with plausible arguments. A model never says “I don’t know.” None of that becomes a reliable production system on its own. The discipline that turns a model into a working agent is harness engineering which is everything wrapped around the model that makes its behavior predictable, auditable, and safe.
The refund that wasn’t
A few months back, I sat in on a triage call for a customer-support agent we’d built on a small model, a cheap, fast, good enough for the routine queries that make up most of the volume. A customer had asked for a refund on a duplicate charge. The agent confirmed the policy applied, called the refund API, got a 200 OK back, and told the customer: “Your refund of $147 has been processed. You should see it in your account within 3-5 business days.”
Except it hadn’t been processed. The 200 response meant the API had received the request. The actual body contained status: "pending_review", the amount exceeded a threshold that required a human approver. The agent saw 200 OK, assumed success, and confidently promised the customer something that wasn’t true.
The customer waited five business days. Nothing happened. They called back angry. Now we had a refund problem and a trust problem.
The temptation was to fix the prompt. Always check the response body. Use exact wording from the API. Don’t say “processed” unless status is “completed.” The prompt got longer. The agent got more cautious. And then it still got things wrong, just in different ways.
The actual fix had nothing to do with the prompt. We layered four harness pieces around the same model:
Output schema validation: On the refund tool’s response. The schema declared that status had to be one of ["completed", "pending_review", "denied"], and the harness forced the agent to acknowledge which value it received.
A status-to-language map: Only "completed" allowed “your refund has been processed.” "pending_review" mapped to specific language about review being underway. The agent could not improvise customer-facing phrasing on this path.
A post-action ledger verifier: Before any success message went to the customer, a separate read against the accounting ledger had to confirm funds had actually moved. No ledger entry, no success message.
An incident hook: If any of the above checks failed, the case routed to a senior rep before the customer heard anything.
After the harness landed, the same small model handled refunds reliably. No prompt changes. The model’s “intelligence” hadn’t improved. What improved was everything around it, bounded responses, schema-enforced status mapping, post-action verification, and an escalation path when uncertainty showed up.
That experience crystallized the discipline for me: the model is rarely the bottleneck, the systems around it are. Cheap small model + good harness reliably beats expensive large model + bad harness.
The formula Mitchell Hashimoto coined captures it:
Agent = Model + Harness
The model is the brain. The harness is everything else, the body that gives the brain hands, eyes, reflexes, and a sense of when to stop.
What a harness actually contains
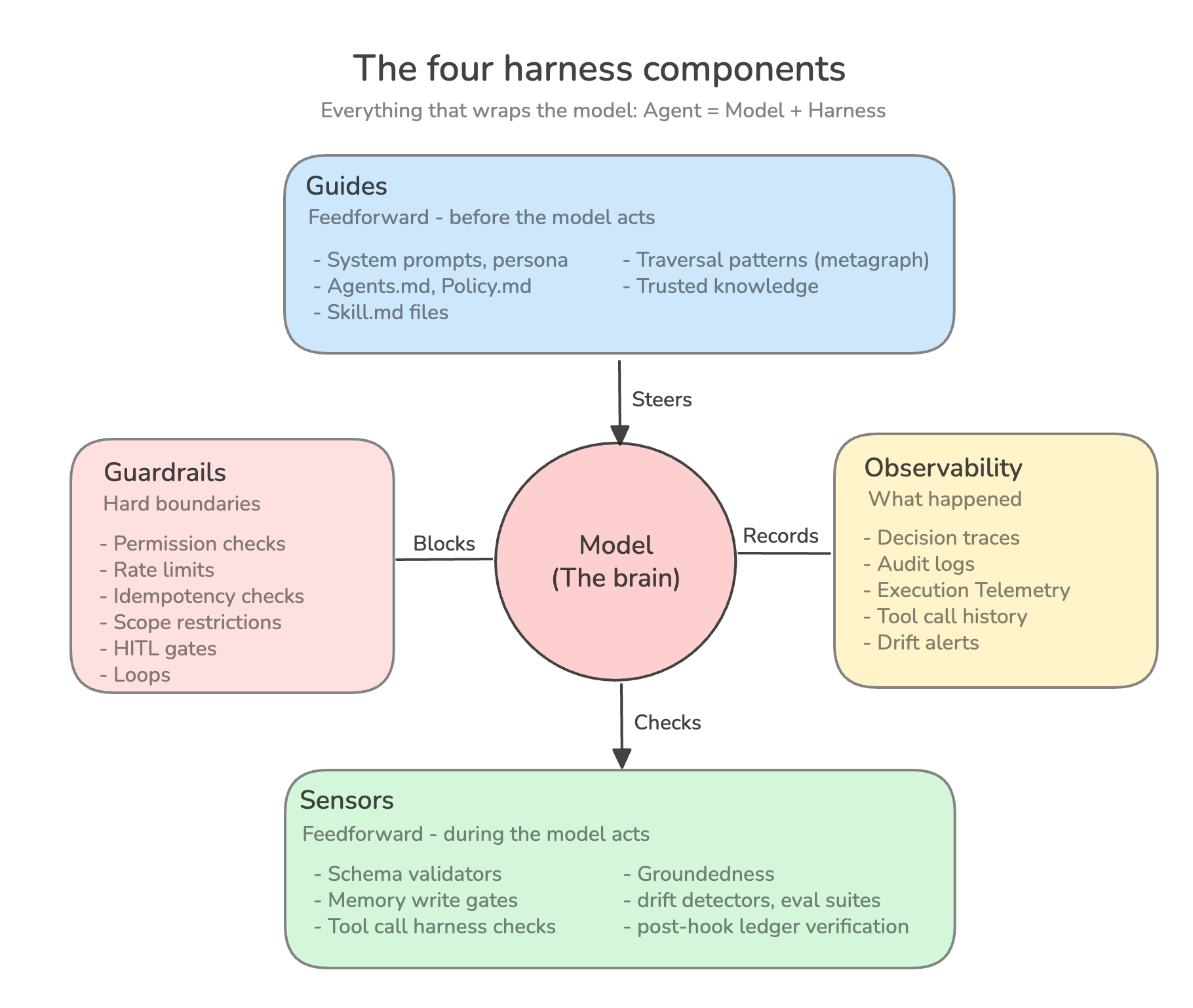
A useful operational definition: if you’re not the model, you’re the harness. Anything in the running agent system that isn’t the model itself which includes, code, config, prompts, hooks, tool descriptions, infrastructure, storage is part of the harness.
That includes the persistent storage substrates the agent reads from and writes to. The context graph from the memory deep-dive is a harness primitive. So are the document store and the vector index sitting next to it and every retrieval flows through them, every memory write lands in them, every audit traces back to them. In a coding-agent harness, this role is played by the filesystem and git; in an enterprise CX harness it’s the context graph, the document corpus, rules on tools and the structured knowledge base.
With that framing, every modern harness has four runtime components. Different teams use different vocabulary, but the architecture is consistent across the literature.
Guides (what to do): Feedforward instructions that steer the agent before it acts. System prompts, compaction prompt constraint documents, agent-readable specifications like CLAUDE.md or AGENTS.md, Skill.md, tool descriptions. Guides direct the model toward the right behavior in the first place.
Sensors (what just happened): Feedback checks that verify behavior after the model acts (or as it acts). Schema validators, output parsers, evaluators, hooks that fire on tool calls, drift detectors. Sensors catch mistakes before they propagate.
Guardrails (what’s forbidden): Hard boundaries the agent cannot cross. Permission systems, rate limits, dangerous-command blockers, scope restrictions.
Observability (what did happen): Telemetry, tracing, audit logs, decision-trace persistence. Observability turns the agent from a black box into a system whose behavior can be reviewed.
Every control runs one of two ways
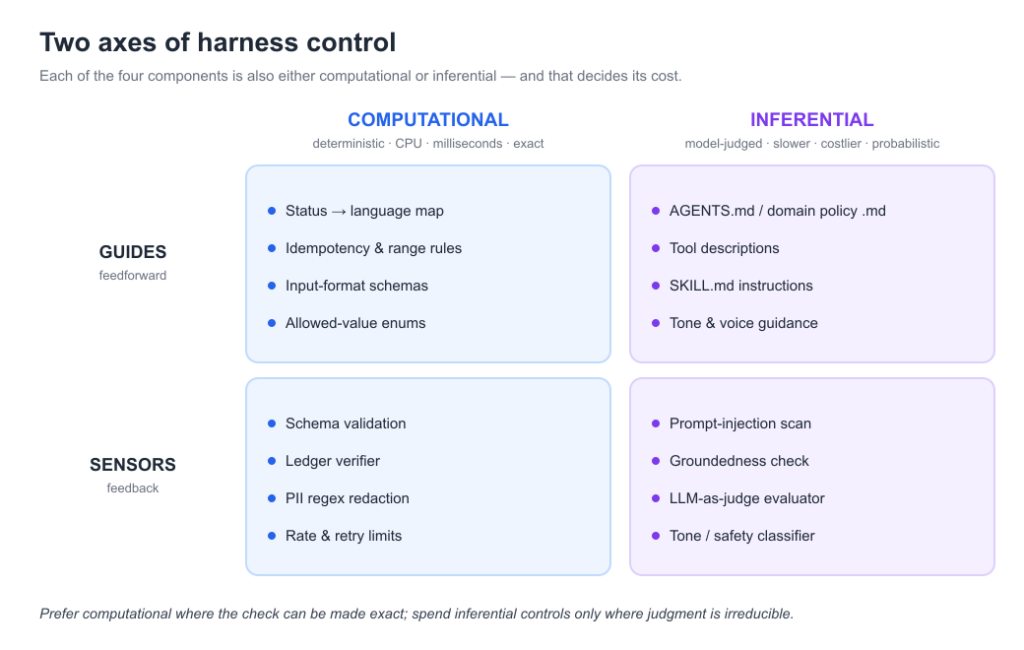
Cutting across those four components is a second axis that decides cost and reliability:
Computational controls: Deterministic, CPU, milliseconds, exact. Schema validators, idempotency checks, the ledger verifier, rate limits, PII regex. Cheap enough to fire every turn.
Inferential controls: Model-judged, slower, probabilistic. The injection scan, the groundedness check, an LLM-as-judge, the natural-language policy the agent reads.
Rule of thumb: use a computational control wherever the check can be made exact; spend inferential controls only where judgment is irreducible. Every inferential sensor is another model call on the critical path, a latency and cost line item, not a free assertion. In Maria’s tally below, most of the twenty checks were computational and effectively free; only the injection scan and groundedness check cost a model call. A harness that reaches for an LLM judge when a schema would do is slow and expensive for no added safety.
Where harness rules actually live
Production harnesses are mostly composed of:
Specification files are .md files that the agent reads.
AGENTS.md / CLAUDE.md at the repo root describe the project’s conventions, dangerous commands, file-modification rules, and the team’s authoring norms. The agent loads these into context at session start.
Per-domain .md files like DEPLOYMENT.md or BANKING_POLICY.md get loaded conditionally when the agent’s task touches that area.
Hooks files — programmatic interceptors around tool calls.
PreToolUse hooks fire before any tool executes. They run schema validation, permission checks, idempotency checks, range checks, rate limits.
PostToolUse hooks fire after a tool returns. They run output validation, ledger checks, side-effect verification.
Hooks are typically authored as small functions in a hooks.py or hooks.ts file and registered with the runtime.
Skill definitions, SKILL.md files (the Anthropic Skills pattern) that bundle tool definitions with usage instructions. These are guides + tool definitions in one artifact, loaded on demand.
MCP servers, the programs that expose tools and resources to the agent through a typed protocol, enforcing access controls and logging at the protocol layer.
Evaluation suites, test runners that replay decision traces against the current harness rules to catch regressions before they ship.
Build order matters
Teams that succeed with an enterprise CX agent harness don’t build everything at once. A practical sequence:
Organizational context first which is the authored surface from the construction-harness section. Before any agent runs, before any tool is registered.
Core guides, the AGENTS.md, domain policy .md files, tool descriptions. Once you have a concrete use case.
Write-tool harness hooks which are schema validations, permissions, idempotency, policy pre-hooks for the first few high-stakes tools.
Workflow tools that encapsulates recurring atomic sequences once a clear pattern emerges in production traces.
MCP servers and external integrations because they expose surfaces that need the harness layers above to be solid first.
Each layer builds on the previous one. Teams that try to start at layer 4 or 5 without the lower layers find that their workflow tools fire against an unreliable substrate and their MCP integrations expose tools the harness can’t gate properly.
Harness during memory substrate construction
So far we’ve talked about harness at runtime, what fires during a live conversation, while the agent is acting. But there is an entire harness discipline that runs before any agent ever sees the substrate: the gates around how content enters storage and how it becomes part of the context graph in the first place.
Two layers, in the order they fire:
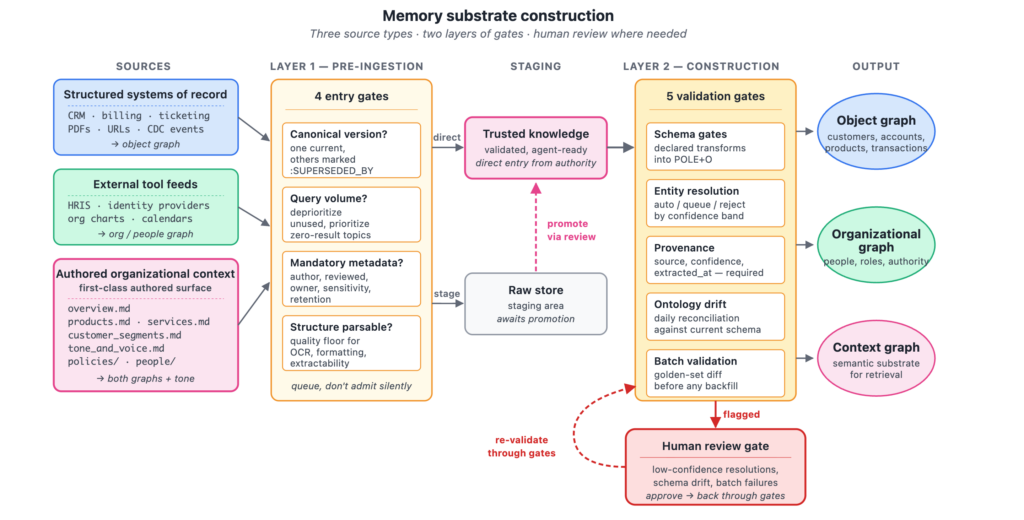
Layer 1 (Pre-ingestion): what earns a place in storage
Before any document, policy, transcript, or organizational fact becomes part of the agent’s substrate, something has to decide whether it belongs there at all. This is the layer most teams skip entirely. They dump every PDF, every wiki page, every meeting transcript into a vector index and call it knowledge. The result is a substrate full of duplicates, outdated drafts, marketing language, and content nobody ever queries.
Pre-ingestion produces records that have passed the entry gate but have not yet been transformed into graph nodes. Content can also enter directly into trusted knowledge when a known authority is the source (a compliance officer publishing a policy, a PM authoring a workflow definition). Both entry paths run through the pre-ingestion gates; trusted entry skips only the discovery gates, not the validation gates.
A pre-ingestion harness asks four things of every candidate source:
Is it the canonical version? A CRM has nine versions of the late-fee policy. One is current. The harness selects the canonical version (by version field, by publication date, by author authority) and rejects the rest as superseded. A :SUPERSEDED_BY edge keeps the lineage queryable.
Is anyone actually asking about this? An operational signal which topics customers ask about, which retrievals return zero results, which conversations escalate because the agent couldn’t find an answer . A document about a discontinued product line with zero query volume earns a deprioritized tier or no place at all.
Does it carry mandatory metadata? Author, last-reviewed date, owning team, sensitivity classification, retention policy. A document without these fields is rejected at the gate, not silently ingested with null everywhere.
Is the structure parsable? A scanned PDF that OCR can’t reliably extract from is queued for human structuring rather than ingested as garbage. The harness has a quality floor for what it will accept.
Sources break into three categories. Each contributes to different parts of the eventual graph and runs through slightly different gates:
Structured systems of record: Documents or urls, CRM, billing, HRIS, ticketing. The pipeline knows their schemas and runs deterministic transforms into POLE+O entities. Mostly contributes to the object graph (customers, accounts, products, transactions).
External tool feeds: Calendar systems, identity providers, organization charts in HRIS, vendor management systems. These contribute primarily to the people and organizational graph (employees, roles, reporting relationships, vendor relationships, departments).
Authored organizational context: This category deserves its own treatment, because it is the place most teams underinvest in.
Layer 2 (Construction): from trusted knowledge to context graph
Once a candidate is in the trusted knowledge , the construction harness governs the transformation into context graph nodes and edges. Five gates fire on every construction pass:
Schema gates on extraction: Every CRM record, every parsed PDF, every authored markdown file maps into POLE+O types through declared transformations. If a source starts emitting a new field, the schema gate flags an unknown property rather than silently dropping it or guessing where it belongs.
Entity resolution gates. When the pipeline thinks Salesforce’s “Maria Lopez” matches FIS’s customer 4421 matches the transcript speaker “Maria,” that’s a probabilistic call. Three modes: auto-merge above 0.95, queue for review between 0.7 and 0.95, reject below the floor. Bad merges are nearly impossible to unwind, so the harness errs toward queueing.
Provenance enforcement: Every node and every edge carries source, confidence, extracted_at, and (for inferred relationships) the extractor version. No provenance, no entry.
Ontology drift detection: Daily reconciliation against the current POLE+O schema. Nodes flagged by drift get queued for re-classification, never auto-rewritten.
Batch validation suites: Sample-and-diff against a golden reference before any backfill lands. Fail the batch if the diff exceeds tolerance.
Conflict-resolution gates: Entity resolution decides whether two records are the same entity; this gate decides what happens when they are but disagree. CRM says tier=Gold, billing says tier=Platinum. Precedence rules resolve the common cases — higher source authority, more recent extracted_at, higher confidence win — and the losing value is retained with a :CONTRADICTED_BY edge, never silently dropped. When precedence is ambiguous, the conflict queues for human review rather than auto-resolving. The same discipline as entity resolution: deterministic where it can be, human where it can’t.
This is the layer that determines whether your graph is a useful retrieval substrate or a quietly poisoned one. The same five gates fire whether the input is a CRM sync, an HRIS feed, or an authored organizational-context file.
The metagraph’s typed-edge traversal patterns play the same harness role for retrieval — they replace fuzzy text search with symbol-precise reads (“walk HAS_TIER then HAS_EVENT to :WaiverEvent nodes”) and dramatically tighten the retrieval surface against irrelevant matches. The discipline differs by domain; the architectural function is the same.
The same principle that governs runtime harness governs construction: every gate is deterministic, every rule traces to a real past failure (a bad merge, a stale doc that misled the agent, an organizational fact nobody had written down). The construction harness is upstream of every retrieval and every decision; getting it wrong propagates everywhere.
One easy diagnostic: if your team can’t answer “where did this graph node come from and what’s its provenance?” in under thirty seconds, your construction harness has holes. The authored-organizational-context surface is the cheapest insurance against the “the agent doesn’t know what we know” failure mode.
A note on what’s missing
The substrate doesn’t stop changing once construction has run. Live conversations produce signals worth folding back in. Decision traces surface patterns that suggest new workflow tools. Slack and Teams threads contain conventions the agent doesn’t know yet. Conflicts between trusted facts surface over time. All of that, the continuous-improvement discipline that turns a static substrate into a learning one is the subject of the fifth pillar, The Learning Loop. The construction harness is what makes today’s substrate trustworthy. The learning loop is what makes it better next week.
Maria’s case, end to end: Harness at every step
Theoretical harness rules are easier to follow when you watch them fire in sequence against a real case. Let’s walk Maria’s $39 late fee dispute from utterance to closed ticket and call out exactly which harness rules trigger at each beat. By the end we will have catalogued every harness check the system actually ran during her case.
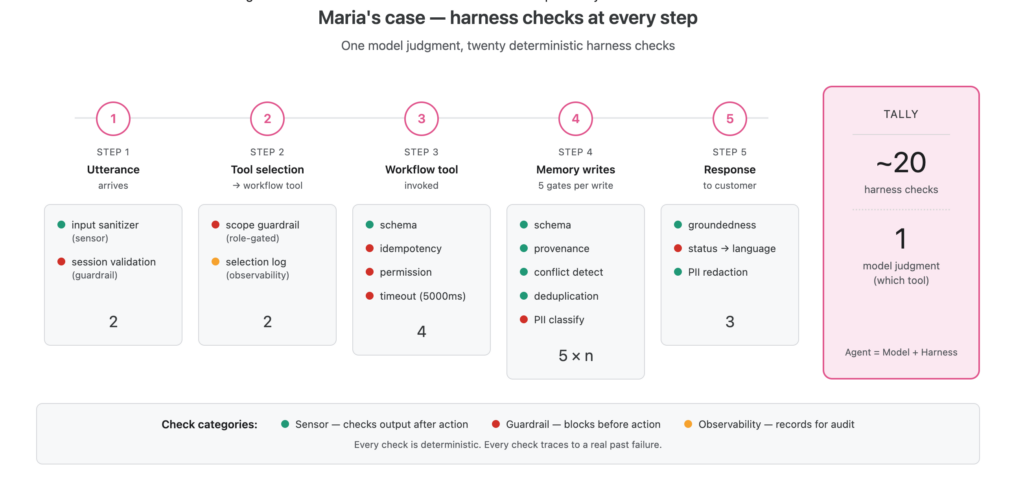
Step 1 ( Utterance arrives):
Maria says: “I want to dispute this $39 late fee on my Platinum card.”
Before the agent ever sees that utterance, two harness layers fire:
Input sanitizer (sensor): The utterance is scanned for prompt-injection patterns, suspicious unicode, and obvious abuse. Pass.
Session guardrail: Maria’s session token is validated against the auth service. Janet, the senior support rep handling the call, is confirmed as the invoking principal. Without a valid session, the agent doesn’t see the utterance at all.
Step 2 (Tool selection):
The agent reads its available tool descriptions and reasons over Maria’s request. late_fee_dispute_workflow is a strong match.
Scope guardrail: Some tools are restricted by role. The harness checks that Janet’s role permits visibility of this workflow tool. A basic-tier rep wouldn’t even see the workflow tool in the catalog. Pass.
Selection observability: The agent’s tool choice, including the alternatives it considered is logged. Six months from now, “why did the agent pick this tool?” is a queryable question.
Step 3 (Workflow tool invocation):
The agent invokes late_fee_dispute_workflow with a single tool call.
Schema validation (sensor): The arguments like customer ID, fee event ID, idempotency key match the workflow tool’s declared schema. Pass.
Idempotency check. The key LFD-CUST_4421-EVT_88291 has not been seen before. If it had been, the harness would short-circuit the call and return the prior result, preventing double execution. Pass.
Workflow-level permission check (guardrail): Janet has the fee_waiver_initiate permission. Pass.
Time-out check: The overall tool should be within 5000ms.
Step 4 (Memory writes during and after execution):
As the workflow runs, each :TraceStep write passes through the five memory-write gates from the memory post: schema validation, provenance tagging, conflict detection, deduplication, and PII classification. Maria’s $39 transaction passes cleanly; had her SSN appeared in the trace, the PII gate would have routed it to a secured store with only a reference token in the graph.
When the case closes, a single :DecisionTrace is written linking all the trace steps to the outcome. The same five gates fire on that write.
Step 5 (Customer-facing response):
The workflow completed cleanly. The agent drafts: “Maria, I’ve waived the $39 late fee on your Platinum card. The reversal should appear on your account within 24 hours.” Three sensors fire before this goes to her:
Groundedness check: Every factual claim, “$39 fee,” “Platinum card,” “within 24 hours” traces back to retrieved evidence or confirmed tool outputs. Pass.
Status-to-language guardrail: waive_fee returned status: "completed", so the phrasing “I’ve waived” is permitted. Had the status been pending_review, this phrasing would have been blocked.
PII redaction: Account numbers, full last names, internal transaction IDs and none slipped into the customer-facing text.
The response ships. The case closes.
A useful tally
The model made one judgment call: which workflow tool to pick. The harness made twenty.
This is what Agent = Model + Harness looks like in operation.
When the harness fails
When the agent does the wrong thing, the question is which harness component failed?
Agent didn’t know a rule → add it to AGENTS.md or a domain .md file (guide gap)
Agent knew the rule but violated it anyway → add a hook to enforce it (sensor gap)
Agent lacked information → add a skill, an MCP server, or a retrieval pattern (context gap)
Agent used a dangerous tool → restrict permissions, add a confirmation gate (guardrail gap)
Agent’s context got polluted with stale or irrelevant content → use a subagent for isolation, or invoke compaction earlier (orchestration gap)
Agent crashed and nobody noticed → add observability and alerting (telemetry gap)
Agent ran in circles → add iteration caps, retry budgets, or convergence criteria (loop gap)
This diagnostic framing turns harness engineering into normal software engineering. Every production incident becomes a debuggable failure with a clear remediation path.
Closing
Three takeaways for the Harness Engineering pillar:
Agent = Model + Harness: Most production reliability lives in the harness, not the model. Cheap small model with a good harness reliably beats expensive large model with a bad harness.
Every harness rule traces to a real failure: Zero aspirational guidance, zero just-in-case guardrails. Each line in AGENTS.md, each pre-tool-use hook, each post-write check exists because the agent did the wrong thing at least once. The harness grows by accretion, never by speculation.
Guides and sensors are both necessary: Guides reduce the probability of mistakes; sensors catch the mistakes that slip through. A harness without sensors is hope; a harness without guides is friction. Real systems balance both, with observability across the top.
One open problem worth naming: there’s no harness coverage metric the way there’s code coverage. If a sensor never fires, is that a clean system or a blind spot? Today you find out when an incident slips through — and add the rule that would have caught it. The harness is never finished; it’s a standing engineering practice, not a one-time config
The fifth and final pillar is The Learning Loop — how the system uses the decision traces, the QA corrections, and the harness incident log to improve over time. The harness catches today’s mistakes. The learning loop turns yesterday’s mistakes into tomorrow’s training data, guide entries, and workflow tools.
Comments
Leave a Comment
No comments yet. Be the first to comment!
Written by Prasanth Sai
Gen AI Product Leader · Leads AI Applications and Search at eGain
I partner with PMs and engineers to drive production adoption of AI across Fortune 500 enterprises in the US and Europe. IIT Bombay alumnus; previously co-founded Selekt.in and built ChatGen.ai. The thesis I evangelize: knowledge is the harness for AI applications.
Enjoyed this article?
Explore more insights on Gen AI, product leadership, and enterprise AI transformation.