Compositional Retrieval: How AI Agents Pull the Right Slice into Working Memory
Prasanth Sai
Updated
15 min read
Share:
This is the second deep-dive in the system of intelligence series. The first covered the memory substrate , the context graph where everything the agent knows about its world is stored. This post is about how the agent gets the right slice of that substrate into its working memory for any given goal, every single turn.
Retrieval is the half of context engineering most teams underinvest in. The other half is compaction, the discipline of keeping the working window healthy as a conversation grows which I have covered in detail in the Ultimate Guide to Context Engineering for AI Agents. This post is the retrieval companion to that piece.
The core argument: pure vector search is not enough. Pure graph traversal is not enough. The pattern that actually works in production is compositional retrieval. The graph narrows the corpus to what is structurally relevant, then hybrid vector search ranks within that filtered set. Anyone who tells you “just use embeddings” has not tried to run an enterprise agent at scale.
This post will walk through:
The retrieval problem and the budget the agent has to solve it within
The three retrieval mechanisms and what each does well and badly
Pre-filtered hybrid search: Entities mapped to metadata filters, then dense + sparse ranking inside one query
Graph traversal at different hop depths: 1-hop, 2-hop, and multi-hop, for everything that is not in the document corpus
Maria’s full retrieval flow, end to end
Retrieving from episodic and procedural memory using the same pattern
The running example is Maria, the Platinum DeltaBank customer disputing a $39 late fee. She has called support for resolution.
1. The retrieval problem
An AI agent operates within a finite working memory budget, approximately 200,000 tokens in modern models which must be meticulously managed to remain effective. The core challenge of retrieval lies in selecting the most critical 25,000–50,000 tokens from a massive enterprise corpus to populate this window for a single interaction. Because this small slice must ground the agent’s reasoning, retrieving the wrong data such as outdated policies or unrelated customer records inevitably results in the agent producing confident but completely incorrect answers.
Naive vector search across the policy corpus alone embedding the query, finding the top 10 nearest chunks runs into lot of failure modes immediately.
Some examples include:
Semantically similar passages from the wrong customer tier. A policy chunk about Gold tier waivers reads as a near-perfect match to “Maria disputes a $39 late fee” because the language is nearly identical, except for the one word that determines eligibility.
The other could be passages from superseded versions of the right policy. The vector index does not know v2 has been replaced by v3.
2. Three retrieval mechanisms
Real systems compose three different retrieval mechanisms. Each one answers a different kind of question, and each one fails alone.
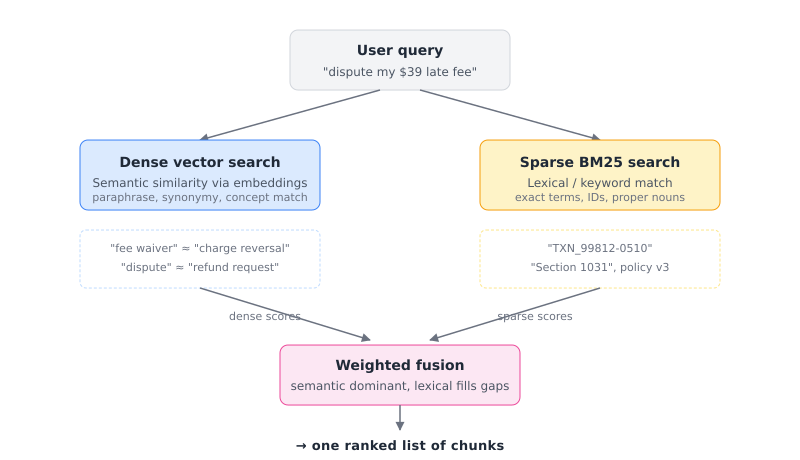
Lexical search (BM25 or similar): Keyword matching. Excellent at exact terms like proper nouns, customer IDs, transaction amounts, policy identifiers. Terrible at semantic equivalence like “fee waiver” and “charge reversal” mean the same thing but BM25 scores them as unrelated.
Dense vector search: Embedding-based similarity. The opposite trade-off. Excellent at semantic equivalence, “fee dispute” and “charge reversal” land near each other in the embedding space. Terrible at exact matches.
Graph traversal: Structural relationships. Excellent at constraint satisfaction like “every Platinum waiver policy authored by Carlos, updated in the last year, with at least one prior decision trace citing it.” No similarity scoring at all. Either the structural relationships exist in the graph or they do not.
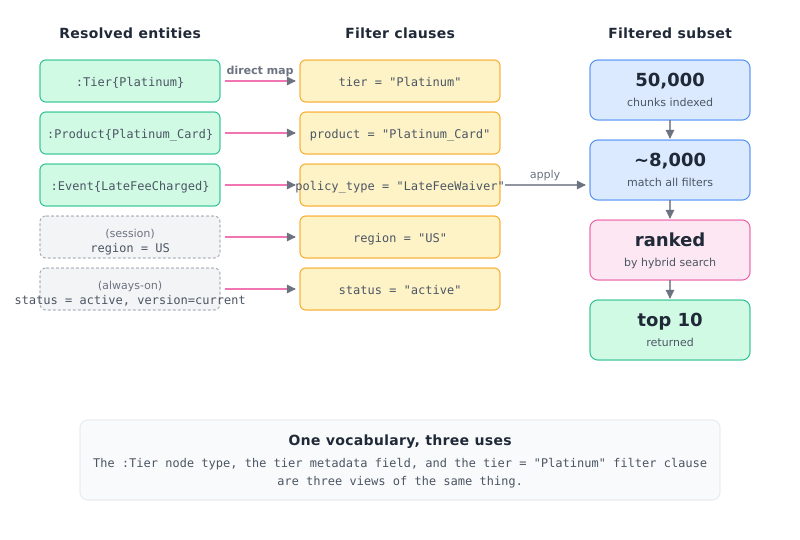
3. Pre-filtered hybrid search
Entities resolved from the query map directly to filter clauses on chunk metadata. Same names, same vocabulary, in both directions.
When the corpus was indexed, every chunk got tagged with structural metadata derived from the same context graph that holds the rest of memory:
At query time, the entities resolved from Maria’s goal map one-for-one onto filter clauses:
Resolved entity
Filter clause
:Tier{Platinum}
tier = “Platinum”
:Product{Platinum_Card}
product = “Platinum_Card”
:Event{LateFeeCharged}
policy_type = “LateFeeWaiver”
(always-on)
status = “active”
(always-on)
version = current
(from session)
region = “US”
The entity types in your context graph and the metadata fields on your chunks are the same vocabulary. The :Tier node type in the graph, the tier metadata field on each chunk, and the tier = “Platinum” filter clause at query. The document chunk index will be filtered with this clause.
Out of 50,000 indexed chunks, perhaps 8000 match all the filter clauses. Hybrid search runs only on those 8000, never on the full corpus.
4. Graph traversal, a structured retrieval beyond documents
The graph is where the agent retrieves everything that is not a document chunk: customer facts, account state, transaction history, past decision traces, workflow steps, applicable rules, precedent. None of this is content the model needs to read; it is structured data the model needs to know.
The graph itself is not one homogeneous database. It is three connected subgraphs, each holding a different memory role, all stitched together as covered in the previous post:
The semantic subgraph: POLE+O entities like customers, products, accounts, locations, events, documents. What is.
The episodic subgraph: Conversations, decision traces, trace steps, outcomes. What happened.
The procedural subgraph: Workflows, steps, rules, heuristics, tools, permissions. How to do things.
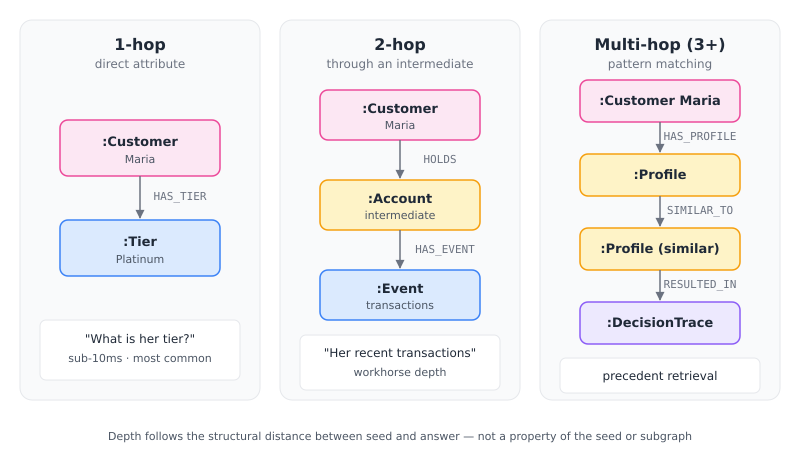
For Maria’s fee dispute, the system runs traversals across all three subgraphs in parallel. Each traversal walks a different subgraph at a different depth, because different questions sit at different distances from the seed entities.
How the traversal happens depends on how far the answer sits from the seed. The variable is hop depth, how many edges you walk from the starting node before stopping.
This is the GraphRAG pattern that recent academic work (HopRAG, StepChain GraphRAG) has formalized: graph traversal complements vector retrieval precisely because some answers cannot be retrieved by similarity alone. They require walking edges that connect facts which are lexically and semantically dissimilar.
Constructing the metagraph
A production system does not run traversals one at a time, ad hoc. For each goal type like LateFeeDispute, FraudClaim, CreditLimitIncrease, NameChange, it maintains a metagraph: a named library of traversal patterns the agent uses to retrieve from the main graph. The term comes from the property-graph standards community, a graph about the graph, holding the schema and the operations defined over it.
Each pattern is a structured specification with five components:
Seed type: What kind of entity to start from (resolved to a specific instance at runtime).
Edge sequence: Which typed edges to follow, in order. Not “all edges from this node”.
Target type: What kind of node the walk ends at.
Filter predicates: Conditions on intermediate or terminal node properties. This is what makes “only waiver events” different from “all events” even when the path is the same.
Depth: How many hops, which is whatever’s required to bridge seed to target given the graph’s structure. Depth is an output of designing the pattern, not an input.
Building a metagraph for a new goal type follows a four-step process:
Decompose the goal into sub-questions: What does the agent need to know to handle this case? Each sub-question becomes its own traversal pattern.
For each sub-question, ask three things of the graph schema: What entity does the answer live on? (target type). What entity is the natural starting point? (seed — usually the central entity for the case). What typed edge path connects them? (edge sequence and, by implication, depth).
Add filter predicates: The path might return too much — all events instead of just waivers this year. Add filters on the target (or on intermediate nodes) to narrow what comes back. Most of the careful design happens here.
Set the budget: Wall-clock cap, max visited node count. Safety rails for cases where the graph turns out denser than the schema suggests.
Hand-authored today in most production systems; the next frontier is learning the patterns from past successful decision traces. Either way, the patterns are stored as a named library, keyed by sub-question, and the runtime looks them up by name at retrieval time.
Where the metagraph lives
A natural question follows: if everything in the agent’s world lives in the context graph including semantic facts, episodic conversations, workflows, rules, tools, where does the metagraph live?
The answer is also in the graph. The metagraph sits in the procedural subgraph, alongside the workflows, rules, and tools it belongs next to conceptually. Each goal type becomes a :GoalType node. Each pattern becomes a :TraversalPattern node connected to that goal type, with properties for the five components (seed, edges, target, filter, depth) and the budget:
This has three benefits over storing patterns in a separate YAML config file:
Same harness, same gates: The harness rules that govern memory writes — schema validation, conflict detection, provenance, PII checks — also govern pattern writes. A bad pattern cannot be silently introduced. Updates flow through the same review and audit path as any other change to memory.
Audit trail through decision traces: Each :DecisionTrace records the specific patterns it used via (:DecisionTrace)-[:USED_PATTERN]->(:TraversalPattern). When something goes wrong six months from now, trace from outcome → decision trace → patterns → reproduce what walked. The full retrieval chain is graph-queryable.
Co-evolution with schema: When an edge type gets renamed or deprecated, every pattern that referenced it surfaces in one graph query. Refactoring the schema goes from a risky exercise in grep-and-pray to a safe traversal.
This is part of why procedural memory is a first-class subgraph in the first place. Workflows describe how to run business processes. Rules describe when to apply policy. Patterns describe how to retrieve from memory itself. They are all how-to knowledge and they all belong in the same store.
5. Compositional retrieval — Maria’s full flow
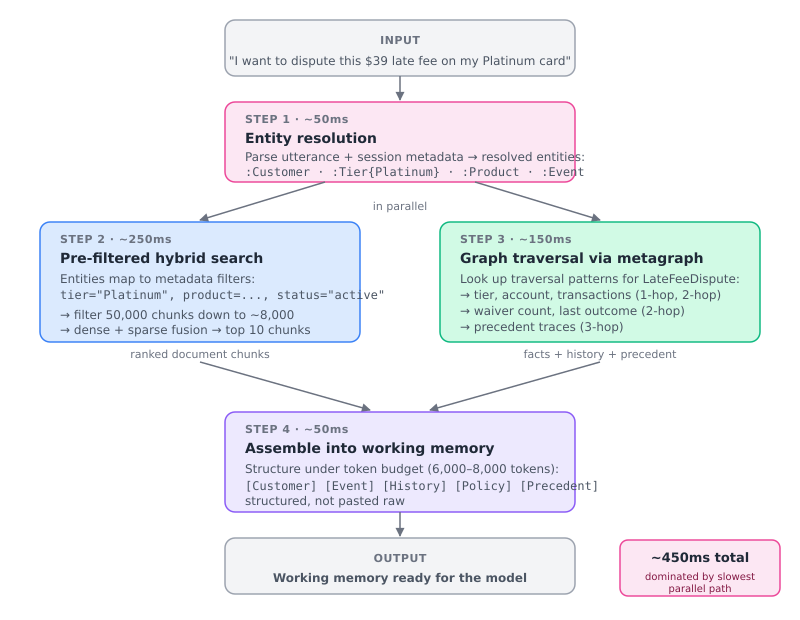
Putting all of this together for Maria’s call, end to end. She has just said “I want to dispute this $39 late fee on my Platinum card.” The system has about 800 milliseconds before the rep takes the call.
Step 0 — Goal classification: Before any retrieval can happen, the system has to know what kind of case this is. Maria’s utterance and her session metadata go to an intent classifier. The classifier returns a label and a confidence score:
intent: "LateFeeDispute"
confidence: 0.94
The classifier reads its candidate labels and example utterances from the :GoalType nodes in the metagraph. Those sample utterances we authored alongside the traversal patterns become its training and few-shot examples. The classification step and the retrieval step share one source of truth.
Step 1- Entity resolution from the goal: A small fast model or named-entity recognizer parses the utterance and Maria’s authenticated session metadata. It produces a set of identified entities:
:Customer {id: "CUST_4421"}
:Tier {name: "Platinum"}
:Product {name: "Platinum Card"}
:Event {type: "LateFeeCharged", amount: 39}
Step 2- Document retrieval via metadata-filtered hybrid search: The resolved entities map directly into filter clauses on the vector store. The query — “What is the policy for a Platinum customer with 0 waivers used this year, disputing a $39 late fee?” — is embedded and run as a hybrid search at α = 0.8, but only over chunks where the metadata matches:
The vector store applies these filters before similarity search runs. Out of 50,000 indexed chunks, perhaps 8000 match all filters. Hybrid search ranks within that 8000, returning the top 10 chunks.
Step 3 – Structured retrieval via graph traversal (parallel with Step 2): For everything that is not in the document corpus — customer state, history, precedent, workflows, rules — the system walks the context graph. To know which traversals to run, the agent uses the traversal metagraph authored for the LateFeeDispute goal type. The traversal in the metagraph for this goal is which was pre-prepared and stored already is done based on the answers the specific sub-questions her case requires:
What is her tier?
What account does she hold?
What transactions has her account had recently?
How many fee waivers has she used this year?
What was her last conversation outcome?
Is there comparable precedent for cases like hers?
What workflow applies to this case type?
What rules govern the current case state?
Each sub-question is one entry in the manifest, with seed, edges, target, filter, and depth fully specified:
Sub-question
Seed
Edge sequence
Target
Filter
Depth
What is her tier?
:Customer
HAS_TIER
:Tier
—
1
What account does she hold?
:Customer
HOLDS
:Account
—
1
Recent transactions?
:Customer
HOLDS, HAS_EVENT
:Event
type="Transaction" AND timestamp > -24mo
2
Waiver events this year?
:Customer
HOLDS, HAS_EVENT
:Event
type="WaiverEvent" AND year=2026
2
Last conversation outcome?
:Customer
PARTICIPATED_IN, RESULTED_IN
:Outcome
most_recent=true
2
Comparable precedent?
:Customer
HAS_PROFILE, SIMILAR_TO, RESULTED_IN
:DecisionTrace
outcome="fee_waived" AND tier="Platinum"
3
Applicable workflow?
:CaseType
HAS_WORKFLOW
:Workflow
version=current
1
Applicable rules?
:CaseState
MATCHES
:Rule
enabled=true
1
Step 4 — Assembly into working memory:
Step 2 returns the ranked document chunks and step 3 returns the structured facts and precedent. Both feed into a structured context block under a token budget . The block is structured, not pasted raw:
[Customer]
Maria Lopez, CUST_4421, Platinum tier since 2023-08-12
Account ACCT_99812, credit, balance $4,250
[Event]
LateFeeCharged $39 on 2026-05-10, caused by PaymentMissed on 2026-05-05
[Payment history]
22/24 months on-time (last 24 months), 2 misses in 2 years
[Waiver history]
0 waivers used in 2026, 1 waiver used in 2024 (approved, similar context)
[Applicable policy — waiver-policy-v3.pdf, section 3.2]
"Platinum customers in good standing may receive one fee waiver per calendar
year at the discretion of the support agent, up to $50, without escalation..."
[Precedent — 3 past decision traces from similar cases]
TRACE_8514: Platinum, 0/year, 95% on-time, $39 fee → waived (approved by Janet)
TRACE_8702: Platinum, 0/year, 88% on-time, $45 fee → waived
TRACE_8108: Platinum, 1/year, 76% on-time, $39 fee → escalated, declined
The agent now has both the structural facts (from the graph) and the relevant policy text (from the vector store with entity metadata pre-filtering), plus precedent from past traces.
This is what compositional retrieval looks like at production. Every box in the pipeline above has a fallback path, a confidence threshold, and a timeout. The retrieval pipeline is itself a small system, not a single query.
6. Retrieval from episodic and procedural memory
Almost everything in the post so far has been about retrieving documents. But the same compositional pattern applies to every other kind of memory the agent might need.
Retrieving past decision traces (episodic memory): Maria’s call is not the first Platinum waiver dispute the system has handled. Six months of operation have produced thousands of past decision traces. When the agent reasons about Maria’s case, surfacing comparable past traces as precedent dramatically improves consistency. Same pipeline: graph traversal first (all :DecisionTrace nodes from cases involving :Tier "Platinum" and :Event "LateFeeCharged" in the last 90 days), then a small hybrid search within that filtered set to rank by similarity to the current case’s facts. The trace nodes themselves are embedded — their thought and observation fields contain the agent’s reasoning, and that text is what the hybrid search ranks against.
Retrieving workflows and rules (procedural memory): The “Late Fee Dispute” workflow is a procedural memory artifact. Its retrieval is almost pure graph traversal — find the active workflow tagged for case type “LateFeeDispute” — no hybrid search needed because workflows are usually unique by case type. Rule retrieval is similar: find every :Rule node where the conditions match the current case state. Pure structural query, deterministic.
The compositional principle is consistent: graph for structure, vector for similarity, hybrid for ranking. The mix shifts by memory type — heavy graph for procedural, heavy vector for documents and episodes, balanced for everything else.
Conclusion
Compositional retrieval is the discipline that makes a context graph worth building. Two mechanisms work in parallel: metadata-filtered hybrid search for retrieving document content, and graph traversal at varying hop depths for retrieving structured data, history, and precedent. The composition — same entity vocabulary across both — is what turns the substrate from the previous post into a working memory pipeline that performs at production scale.
Three takeaways worth carrying forward:
Retrieval is not search: Search returns ranked documents. Retrieval assembles a working memory — structured facts plus relevant content plus precedent plus procedural guidance, all under a token budget, in well under a second.
The pre-filter dominates: Metadata filtering matters more than ranking quality within the filtered set. The same entity types in your context graph become the metadata fields on your chunks and the filter clauses at query time.
Hop depth is a deliberate choice: Not every graph query is multi-hop. Direct attribute lookups stay at 1-hop. History and direct context use 2-hop. Reserve multi-hop traversal for the cases that actually need it — precedent retrieval, connection discovery, compositional reasoning across policies. Cheaper queries done at the right depth beats expensive queries done at maximum depth.
The next pillar in the series is Tools and Actions — the typed connectors that let the agent act back on the systems of record once it has reasoned over its working memory. Retrieval gets the right content in. Tools turn the agent’s decisions into changes in the world. The two pillars together are what separate a chatbot from a system of intelligence.
For the rest of the context engineering discipline — compaction, scratchpad management, freshness, and what happens when working memory grows beyond budget mid-conversation — see the ultimate guide to context engineering.
Comments
Leave a Comment
No comments yet. Be the first to comment!
Written by Prasanth Sai
Gen AI Product Leader · Leads AI Applications and Search at eGain
I partner with PMs and engineers to drive production adoption of AI across Fortune 500 enterprises in the US and Europe. IIT Bombay alumnus; previously co-founded Selekt.in and built ChatGen.ai. The thesis I evangelize: knowledge is the harness for AI applications.
Enjoyed this article?
Explore more insights on Gen AI, product leadership, and enterprise AI transformation.