This is the first deep-dive in the system of intelligence series. The overview post laid out five pillars: memory, context engineering, tools, harness, and the learning loop. This post is about pillar one, the substrate where everything the agent knows about its world is stored.
Memory is the foundation. The other four pillars do nothing useful if memory is incomplete, stale, contradictory, or wrong. Context engineering can only surface what memory contains. Tools can only act on what memory describes. The harness can only validate against what memory says is policy. The learning loop is only as useful as what gets written back into memory.
We will cover five things in turn:
What memory actually is, and how it differs from what most teams think it is.
The trusted vs raw knowledge distinction that the rest of the architecture rests on.
What a context graph is and how you construct one from your existing systems.
What the harness has to do at the memory layer including how content earns promotion from raw to trusted.
How memory stays fresh, the writes, the propagation, the decay, the garbage collection.
The DeltaBank example from the overview runs throughout. Maria is the Platinum cardholder calling to dispute a $39 late fee. We’ll look at the slice of memory that her call touches.
1. What memory is
There are 3 layers of Memory for AI Agent
Current memory: The context that is present in the current turn for LLM to execute and come up with an output.
Short-term memory: The scratchpad that AI agent keeps throught the session and removes it after the session ends
Long-term memory: All the decisions that AI agent has taken, things learned about the user or company, company decisions and external knowledge that is available to AI agent.
Here in this post I will be talking about Long-term memory, the persistent store of everything the agent might need to know about its world. The CRM record of every customer. The text of every policy document. The history of every conversation. The decision the agent made on call #4,212 last Thursday and why.
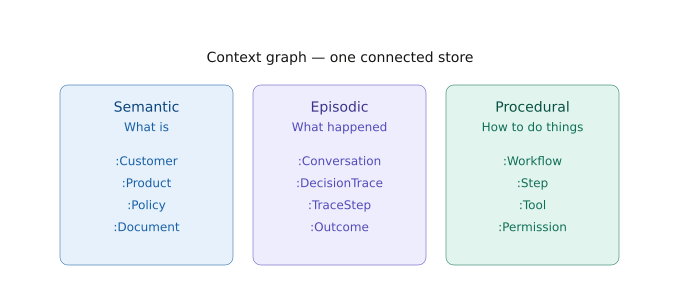
A useful taxonomy comes from the CoALA framework, which adapted cognitive psychology for LLM agents. It distinguishes three roles long-term memory has to play:
Semantic memory: Facts about the world. Maria is a Platinum customer. Her card has a $39 late-fee policy. Carlos owns the late-fee waiver policy. Stable, queryable, updated when the world changes.
Episodic memory: Past interactions, time-stamped and conversation-anchored. On May 12 at 2:47pm, Maria called about a billing inquiry. The agent pulled three policy docs and resolved the case in 95 seconds. A structured subtype that has emerged as its own discipline is reasoning memory — the agent’s own thought-action-observation steps captured as decision traces. Reasoning memory isn’t a fourth role; it’s what episodic memory looks like when you take the agent’s internal reasoning seriously and store it alongside the external events.
Procedural memory: Workflows, rules, templates, heuristics, tool definitions. Late-fee disputes follow these seven steps. Platinum customers under one waiver per year are auto-eligible up to $50. The waive_fee tool requires the fee_waiver_apply permission.
In most enterprise stacks today, the three roles are scattered. Semantic memory lives in the CRM. Episodic memory lives in call logs or a conversation table. Procedural memory lives in workflow tools or knowledge base platforms. This separation is the single largest source of system-of-intelligence dysfunction.
The premise of a context graph is to collapse that federation into the substrate itself.
2. Raw knowledge vs trusted knowledge
A distinction worth naming before we get into graph mechanics:
Raw knowledge: Every source the system has ever ingested. Documents, transcripts, CRM dumps, Slack threads, URLs, manually-pasted policy text. Untransformed, source-of-truth versions, with provenance attached.
Trusted knowledge: The validated subset that lives in the context graph and its document/vector stores. This is what retrieval and traversal actually consult.
Trusted knowledge is constructed from raw knowledge through the harness gates we cover in Section 4. Both layers persist; neither is throwaway. Raw is the provenance anchor that lets you ask “where did this trusted fact actually come from?” six months later.
Content enters the system at one of two layers:
Direct to raw: Bulk imports, CRM CDC, document drops, Slack/Teams ingestion, conversation harvesting. Cheap to admit, not yet usable. The harness still has to graduate it.
Direct to trusted: Manual curation by a known authority. A compliance officer publishing a policy. A PM authoring a workflow definition. An SME correcting a fact. Skips the discovery gates because a trusted human is the discovery gate. Still runs the write gates (schema, provenance, conflict detection, dedup, PII).
The architectural rule: trusted knowledge has two construction paths but one validation discipline. Manual curation does not get to skip the write-gates; it gets to skip the discovery-gates.
This vocabulary, raw vs trusted runs through the rest of the post and the rest of the series.
3. Graphs and how a context graph is constructed
A context graph is a single connected graph that holds all three memory roles together which has one database, one query language, shared entities as the same node across roles.
Why a graph, not a bigger vector store
Vector search and graph traversal answer different questions.
Vector search answers semantic questions: what does the policy say about waivers above $50? It works by similarity, passages whose embeddings are nearest to the query’s.
Graph traversal answers structural questions: every Platinum waiver policy authored by Carlos and updated in the last year, alongside the prior decision traces that cited each one. No embedding model ranks that correctly. It’s a structural query with nodes, edges, traversal.
Real systems use both. The graph is the catalog and the relationship map; the vector store holds the prose. We will get to the retrieval side in the next post. This post is about what the graph holds.
POLE+O — a starting taxonomy
Neo4j’s recent work on context graphs popularized an entity taxonomy worth borrowing wholesale. They call it POLE+O, a five top-level entity categories that cover most enterprise domains:
Category
DeltaBank examples
P
Person
Maria, Carlos (policy owner), Janet (senior rep)
O
Organization
DeltaBank, Card Services dept, Visa
L
Location
San Francisco, Chicago HQ, Manila call center
E
Event
Payment missed, late fee charged, support call
+O
Object (everything else)
Platinum card, account, waiver policy, policy PDF
POLE+O is a starting point, not a finished taxonomy. Every domain has entities that resist neat categorization. A ‘contract’ is an object, an event, and a relationship all at once and some domains will need additional or different top-level categories entirely. Healthcare might add :Condition and :Procedure as first-class categories. Manufacturing might add :Part and :Process. Logistics might split :Location into :Origin and :Destination. The point of starting from POLE+O is not that these five categories cover everything; it is that the categories that do fit transfer cleanly across domains. A :Person in your banking model is a :Person in your fraud-detection model. You compose ontologies on top of POLE+O rather than reinventing the basics for each use case.
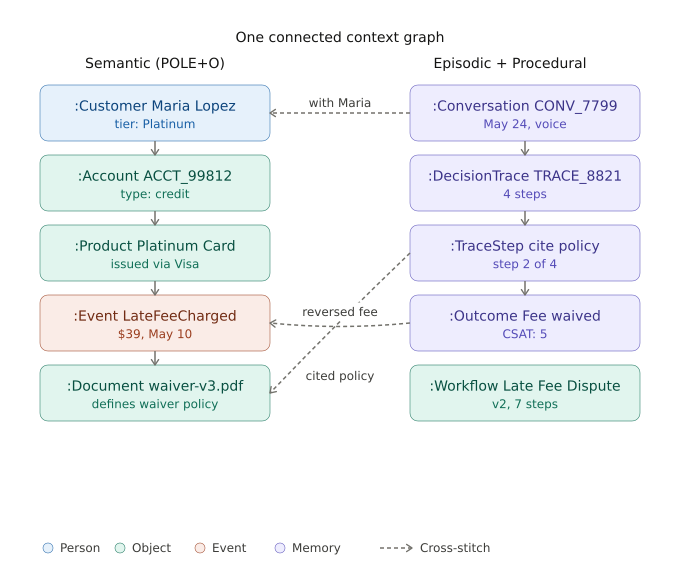
For Maria’s late-fee dispute, the slice of the graph that the system needs spans all three memory roles and all five POLE+O categories.
The arrows are the point. Maria the customer (semantic) is the same node as Maria the participant in CONV_7799 (episodic) is the same node as Maria the subject of TRACE_8821 (reasoning). The waiver policy doc cited inside the decision trace is the same node that defines the policy that applies to her tier. Carlos who authored the doc is the same node as the employee in Card Services who reviews escalations.
This cross-stitching is what “show me every Platinum waiver decision in the last 90 days, the policy citation the agent used in each one, and which doc author wrote that policy” becomes a single graph query — instead of three queries against three systems joined by string-matching on names.
Five sources feed the graph
The graph doesn’t spring into existence. It’s constructed from five sources, each contributing different parts of POLE+O.
1. Extraction from systems of record. CRM, billing, HRIS, ticketing systems each have their own schema. DeltaBank’s Salesforce holds customer records → :Customer nodes. FIS Card Management holds card and transaction data → :Product, :Account, :Event nodes (with :LateFeeCharged and :PaymentMissed as event subtypes). ServiceNow tickets → :Ticket nodes. Each source maps into POLE+O with explicit transformations that get reviewed like schema migrations — because that’s what they are. Mostly contributes to the object graph.
2. Extraction from documents. Policy PDFs, training materials, call transcripts, emails. NER pulls out people, products, policies, and events. Relation extraction infers the edges (this PDF mentions Platinum tier; this section governs late-fee waivers; this transcript involves customer 4421). Full text gets chunked and embedded into a vector store. The graph keeps the :Document node, its metadata, and pointers.
3. Operational writeback. Every conversation generates :Conversation, :DecisionTrace, and :TraceStep nodes. Every tool call generates an :Action node linked to the :Tool it invoked and the resulting :Outcome. This is the agent writing to its own memory in real time — what makes the graph a living artifact.
4. External tool feeds. Calendar systems, identity providers, org charts in HRIS, vendor management. Contributes primarily to the organizational graph which contains employees, roles, reporting relationships, decision authority.
5. Authored organizational context. The source most teams under-invest in. The context graph cannot be built entirely from structured sources. The most important content, what does this organization actually do, who are its customers, what is its tone, what are its non-negotiables exists nowhere as a structured record. It lives in people’s heads, in scattered docs, in onboarding decks. If the agent can’t see it, the agent can’t use it.
A serious construction process creates a dedicated authored surface inside trusted storage, a templated folder where humans write about the organization itself, with a fixed schema and a review path:
/trusted_knowledge/organization/
overview.md # mission, business model, scale
products.md # product catalog
services.md # service offerings with SLAs
customer_segments.md # tier definitions
tone_and_voice.md # communication norms, what NOT to say
policies/ # escalation, authorization, regulatory
people/ # org chart, decision authorities
Every file carries mandatory metadata (author, last-reviewed date, owning team), and goes through review. The construction pipeline parses these files into the object graph (products, services, segments) and the organizational graph (people, roles, authority), enriching what structured systems provide. Without this surface, the agent knows about Maria’s account from the CRM but not about DeltaBank’s tier philosophy.
The hard part: entity resolution
Building a context graph is harder than building a knowledge graph for one reason: entities have to match across sources.
Salesforce’s “Maria Lopez” with email mlopez@gmail.com has to be the same node as FIS’s customer ID 4421 has to be the same node as the speaker named “Maria” in the call transcript from May 12. If they end up as three different nodes, the cross-stitching collapses and you’re back to federation.
Entity resolution: matching, deduplication, conflict handling etc., is the most under-discussed and most consequential piece of context graph construction. It’s also where the harness does its hardest work, which is the next section.
4. Updating the context graph
The graph is not built once. It’s continuously updated by extraction pipelines, by every customer conversation, by every policy refresh, by every human correction. The discipline of updating the graph is what separates a context graph from a database snapshot.
Memory has a failure mode that doesn’t exist for stateless systems: bad writes are permanent. A stateless model can produce a wrong answer in one turn and a right answer in the next. A bad fact written to memory poisons every retrieval that touches it, until somebody finds and removes it. Six months in production with no update discipline, and the graph isn’t a context graph anymore, it’s a slow-motion data quality incident.
Six things govern updates, in order:
Where updates come from, the four categories of writes
The harness gates, validations that run on every write
Promotion from raw to trusted, the design choice that determines what becomes agent-visible
The correction interface, when gates miss things
Propagation, what cascades when trusted knowledge changes
Substrate hygiene, long-term care of the graph
4.1 Where updates come from
Four categories of writes keep the graph current.
Conversational writeback: Every conversation produces :Conversation, :DecisionTrace, :TraceStep, and :Outcome nodes. This is how the agent learns from its own work. Maria’s call generates a trace showing why her fee was waived; six months from now, another agent handling a comparable case can retrieve it as precedent.
System-of-record synchronization: When Salesforce updates Maria’s address or FIS posts a new transaction, the graph catches up via change data capture, a stream of updates from each source. Latency targets vary: customer-facing agents need sub-second propagation for transactions, tier changes can tolerate minutes.
One important rule: trusted knowledge does not auto-sync from sources by default. Once a fact has been validated and entered trusted, it is locked. Source updates flow into raw, where they trigger re-validation through the harness before they can update the trusted layer. For sources, the team trusts upstream (compliance-managed policy hubs, billing systems for transaction data) the team can explicitly opt in to auto-sync. The default is prompt on promotion — when content first promotes, the system asks whether to keep syncing or treat trusted as canonical.
Document refresh: When waiver-policy-v3.pdf gets replaced by waiver-policy-v4.pdf, the graph creates a new :Document node, links it to the :Policy it defines, and marks v3 as superseded. Old decision traces that cited v3 still point at v3 — version preserved for audit, new retrieval surfaces v4. Nothing is deleted.
Learning loop writeback: When a human QA reviewer disagrees with an agent’s decision, their correction becomes a new :DecisionTrace node with :Outcome {reviewed_by: human, correct: false, correction: ...}. Tomorrow’s retrieval picks these up as cautionary precedent. The loop closes.
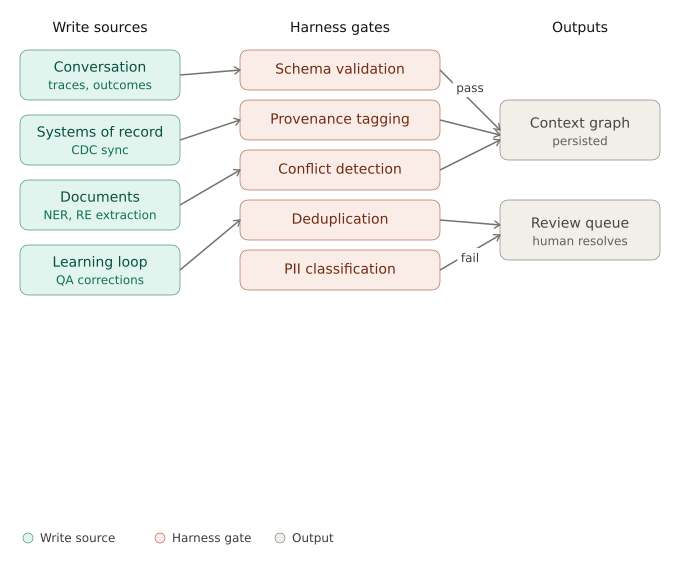
4.2 The harness gates – checks on every write
Every write, regardless of source, passes through some deterministic gates before it lands in the graph.
Schema validation: Every node and edge has to match a declared type. A :Customer must have an id, a tier, and a created_at. A :LateFeeCharged must have an amount and a charged_to edge to an :Account. Catches the most common failure: an extraction pipeline that started emitting nodes in a slightly different shape after a model upgrade.
Provenance metadata: Every node carries source, confidence, and timestamp. Extracted from a PDF → points back at the PDF. Learned from a conversation → points back at the conversation. Human-curated → points back at the curator. Provenance is what makes audit possible six months later — and what powers the next check.
Conflict detection: New writes that contradict existing high-confidence facts get flagged. If Salesforce says Maria’s tier is Platinum and a new extraction from a call transcript says Standard, the conflict goes to a queue, not into the graph. The harness doesn’t resolve contradictions — it surfaces them. Resolution is human work or, occasionally, a deterministic rule (system-of-record beats inference).
Deduplication: Entity-resolution decisions are writes the harness has to gate. The system linking FIS’s “M. Lopez” to Salesforce’s “Maria Lopez” makes a probabilistic call. Below threshold → review queue, not merge. Bad merges are nearly impossible to unwind; they create knots of incorrect cross-stitches that propagate through every retrieval.
PII classification and scoping: Some facts should never live in semantic memory. A customer’s SSN extracted from a call transcript doesn’t get a :Property node — it routes to a secured store, with the graph holding a reference token instead. Sensitive data that does belong in the graph gets scoped: only certain queries, from certain roles, can traverse to it. Enforced at write time and again at read time.
The pattern is intercept-validate-or-reject — the same shape as the harness around tool calls. The difference: memory-write consequences are slower-burn. A bad tool call hurts one customer in one turn. A bad memory write hurts every customer whose retrieval touches it for the next six months. Memory deserves more harness scrutiny than tool execution, not less. Most teams have it the other way around.
4.3 Promotion from raw to trusted
The five gates above run on every write. But the question of which raw content earns promotion to trusted in the first place is a design choice — one the team has to make explicitly per use case. The harness on promotion is not one rule; it’s a use-case-specific policy.
Two paths exist, and most production systems use both.
Path 1 — Human-reviewed promotion
For high-stakes domains where a bad fact in trusted memory has real consequences — customer-facing agents in support, banking, healthcare, legal, compliance — the default is every piece of content lands in raw and waits for a human to approve promotion. No auto-promotion, regardless of confidence or source pedigree.
A single incorrect trusted fact in these domains gets cited as authority in dozens of customer-facing responses before anyone notices. A wrong policy ceiling, a misattributed product feature, a mistakenly-merged customer record — each becomes the agent’s confident answer to every matching question for weeks. The cost of a bad trusted fact far exceeds the cost of slower promotion.
Path 2 — Auto-promotion rules authored by the team
For lower-stakes domains — internal knowledge bases, engineering documentation, exploratory analytics, internal-only agents — full human review on every promotion is overkill. Teams instead author deterministic auto-rules that codify their trust model.
The principle is unchanged: humans define how trust gets earned. What differs is that the team writes those rules once and the harness enforces them automatically thereafter. Concrete auto-rules teams write:
“Any document authored by Compliance and reviewed by Risk auto-promotes.”
“Confluence pages in /engineering/standards/ with a non-null owner field and a last_reviewed date inside 90 days auto-promote on every CDC sync.”
“Salesforce records where record_type = Product and lifecycle_stage = GA auto-promote; anything in Beta stays in raw.”
“HRIS employee records auto-promote, except those flagged confidential = true which always require human review.”
“Facts extracted with confidence ≥ 0.95 and corroborated by at least two independent sources auto-promote. Single-source facts at any confidence stay in raw.”
Useful default: start with everything human-reviewed, then graduate specific patterns to auto-rules once the team has watched them work for a quarter. Teams that flip this — starting with auto-rules and trying to add review later — discover that bad content has already spread. Promotion rules are easy to relax and nearly impossible to tighten without expensive cleanup.
4.4 The correction interface – when gates miss things
Even good harness rules miss things. A new extraction pipeline produces nodes in a subtly off shape and the schema validator passes them because the shape isn’t technically wrong, just suboptimal. A conflict-detection rule fires and a human reviewer approves the wrong side. Two customer records that looked like the same person got merged — actually they’re a parent and an adult child with the same name and address. Six months later, the graph contains a knot of incorrect cross-stitches that have propagated through every retrieval.
The harness is the automated safety net. The human safety net underneath it is a UI that lets reviewers see the graph, find the suspect slice, and fix it.
What it needs:
Inline graph visualization: Pick a node, see its neighborhood, pan, zoom, expand relationships. (Native tools exist for every major graph DB: Neo4j Bloom/Browser, Memgraph Lab, TigerGraph GraphStudio. Commercial platforms like Linkurious and Hume add workflow features. JS libraries like G6, Cytoscape.js, yFiles cover custom rendering.)
A review queue with a diff view: Proposed change next to existing graph, edges colored by source.
Provenance filters: “show me every node added in the last week from document extraction with confidence below 0.7.” Triage by source, extractor version, confidence band, time window.
Bulk operations: When a regression creates 3,000 nodes with a wrong relationship type, fix them in one operation.
Audit logging: Every manual correction becomes a :CorrectionEvent node — who edited what, when, why, against which prior state. The audit log is itself memory.
Re-validation on correction: When you split a merged entity or fix a tier label, the harness re-runs every check that touched the affected nodes and re-evaluates the cross-stitches downstream.
The most important thing about this layer: it’s not optional. Most context graphs in production have a graph database, a harness, and a writeback pipeline — but no first-class correction interface. When something goes wrong, the fix happens through ad-hoc Cypher queries in production, by the engineer who built the system, with no audit trail. It’s a data-quality time bomb waiting to detonate the first time an auditor or a customer asks “how did this incorrect fact get into the system?” and the only honest answer is “we don’t know.”
4.5 Propagation — what cascades when trusted updates
Every update to trusted knowledge cascades through the rest of the system, but the cascade is not uniform. Different artifacts have different review bars:
Context graph nodes and edges: Auto-update. The five harness gates fire on the update.
Tool descriptions: Auto-update within bounds (description tweaks); new tools require human review.
Workflow definitions: Human review, versioning bump.
Metagraph traversal patterns: Human review required. Traversal patterns govern how the agent reasons, not just what it knows. A drift in metagraph is a drift in behavior, and that bar is higher.
The architectural rule: the more an artifact governs the agent’s behavior, the higher the review bar for changes. A fact correction propagates automatically. A traversal-pattern change requires sign-off.
Beyond writes and propagation, four maintenance disciplines keep the graph from accumulating noise.
Decay: Some facts are inherently time-bound. Maria’s account balance from last Tuesday is not relevant by Friday. The graph either expires these facts (delete the node) or moves them to a time-series store with a pointer from the graph (preserve audit, free the working substrate). Choice depends on data type and audit requirement.
Supersession: Versioned facts — policies, product definitions, org assignments — never get deleted. They get marked superseded. Carlos used to own the waiver policy; he handed it to Priya in March. The graph holds (Carlos)-[:OWNED_UNTIL:2026-03-01]->(Policy) and (Priya)-[:OWNS_SINCE:2026-03-01]->(Policy). Both edges exist. A query for “current owner” filters by status; an audit query for “who owned this in February” returns Carlos.
Consolidation: Patterns observed across many decision traces become candidates for procedural memory. Across 200 Platinum waiver decisions, the agent has consistently approved cases where payment-on-time ratio is above 90% — that’s not just episodic data anymore, it’s a candidate pattern worth encoding. A consolidation pass extracts the pattern and proposes it for human review. The reviewer (PM, SME, or knowledge owner) decides what to do with it. Three outcomes are common:
Update an existing workflow
Author a new workflow tool
Add a :Heuristic node
The proposal-then-review pattern matters: consolidation never silently writes to procedural memory. A human always decides whether the pattern is worth encoding and which shape it should take.
Garbage collection: A continuous-scan discipline that surfaces content gone stale or low-value. The scanner flags:
Stale policy docs (last-reviewed past threshold)
Drifting workflow tools (success rate degrading)
Low-groundedness decision traces (succeeded but with weak evidence)
Orphan graph nodes (created but never retrieved)
Duplicate chunks (from re-ingestion)
Outdated metagraph patterns (high hop count, low precision)
Flagged content doesn’t auto-delete. It surfaces to a queue where a human decides: refresh, archive, or remove. Without this discipline, the substrate accumulates rot — and rot compounds, because the agent replicates patterns it sees, even bad ones.
Conclusion
Memory is the substrate. It’s what the agent knows. Everything else in a system of intelligence either reads from it (context engineering), acts on what it describes (tools), validates against what it says is true (harness), or writes back into it (learning loop).
Five design commitments separate a memory substrate from a database:
Unification — all three CoALA memory roles live in one connected graph, not three federated stores.
Raw vs trusted split — raw is the provenance anchor; trusted is what the agent reads. Promotion is a use-case-specific design choice.
Construction discipline — entities resolved across sources, schema enforced, provenance tracked, organizational context authored as a first-class surface.
Update harness — five gates on every write, plus a correction UI when gates miss, plus a clear propagation hierarchy for cascading updates.
Living maintenance — conversational writeback, sync from systems of record, document refresh, learning loop corrections, decay, supersession, consolidation, and garbage collection running continuously.
The memory substrate is one of four disciplines that operate together. The construction harness builds it. The runtime harness protects it during live cases. The learning loop grows it based on observed need. The garbage collector keeps it clean. Four disciplines, one substrate. This post covered the substrate itself and the harness piece that gates updates into it. The next three posts cover the rest.
In the next post, we cover Retrieval with the Context Graph — how the agent traverses and queries the substrate we’ve built here, and how the graph pre-filters what vector search has to look at.
Comments
Leave a Comment
No comments yet. Be the first to comment!
Written by Prasanth Sai
Gen AI Product Leader · Leads AI Applications and Search at eGain
I partner with PMs and engineers to drive production adoption of AI across Fortune 500 enterprises in the US and Europe. IIT Bombay alumnus; previously co-founded Selekt.in and built ChatGen.ai. The thesis I evangelize: knowledge is the harness for AI applications.
Enjoyed this article?
Explore more insights on Gen AI, product leadership, and enterprise AI transformation.